
Stem Storytellers Fellowship
Final talks for cohort 3:
2020-2021 Fellows:
- Sobia Anjum, Chemical and Biological Engineering
- Hannah Duff, Land Resources and Environmental Science
- John Russell, Chemistry and Biochemistry
- Erin Taylor, Chemistry
- Mallory Thomas, Microbiology and Immunology
- Ghazal Vahidi, Engineering
- Galip Yiyen, Chemistry and Biochemistry
Recent Podcasts by the STEM Storytellers
R Script
This R script can be copied and pasted into R. In R, the script will read an input file or multiple input files and calculate the amount of jargon present in the file(s). It will also create a list of words that may be jargon, so the writer can consider those words when writing for a general audience. An optional zip file contains pre-assembled corpora, as well as two example files.
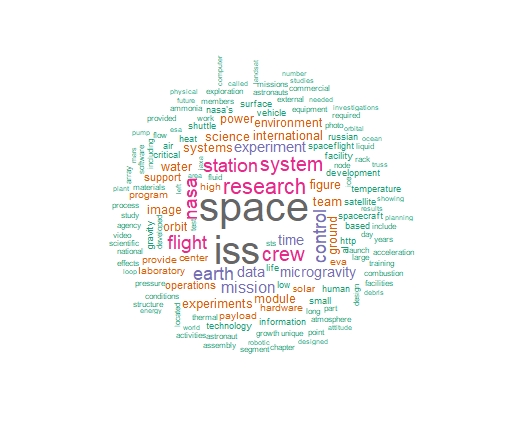
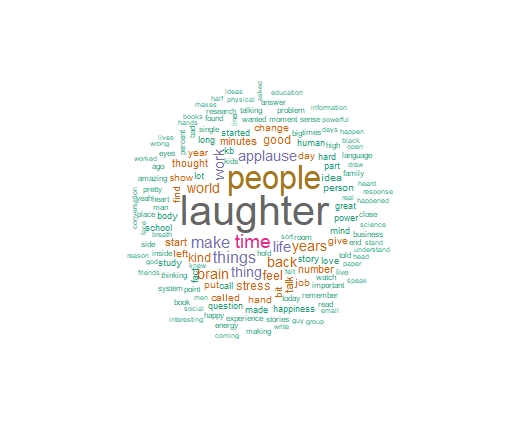
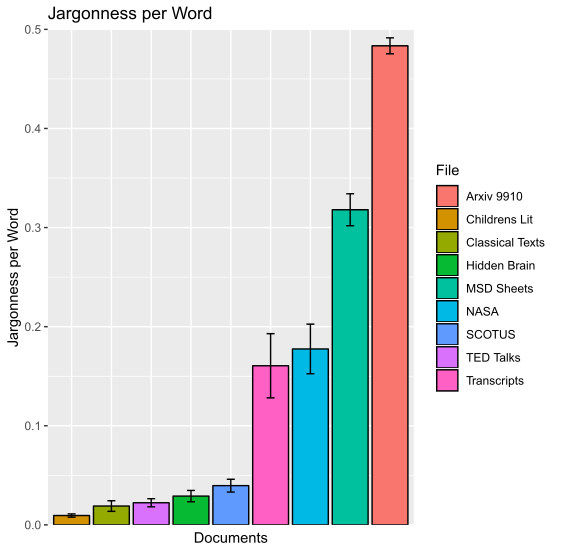
Below is a graph of the documents we have used to benchmark j values. Also shown are two word clouds, and it can be seen that the majority of words spoken in TED talks are quite different than the majority of words in NASA E-books
Funded by the National Science Foundation, grant #1735124. 